2. Literature Review Draft: Work in progress
Introduction to Multiligual translation Framework
Background:
Brief Introduction:
When exploring the matter of Multilingual NLP, Dr. Benjamin Elson’s 1987 Linguistic Creed comes to mind.
“As the most uniquely human characteristic a person has, a person’s language is associated with his self-image. Interest in and appreciation of a person’s language is tantamount to interest in and appreciation of the person himself. All languages are worthy of preservation in written form by means of grammars, dictionaries, and written texts. This should be done as part of the heritage of the human race.”
In the realm of cross-lingual or multilingual natural language processing (NLP), it does appear that some languages tend to garner more attention. Typically well-established languages, with a plethora of linguistic resources to build from, often thrive while low-resource creole languages are left to languish. Creoles are a particular challenge of the NLP community as these languages often arise from often frantic and urgent needs to establish harmony in communication within cacophonous settings. In the Caribbean, creole languages often emerged as a means of survival, and endured as a result of resilience; often speakers struggled to work within the bounds of a dominant prestige language while retaining unique traces of their heritage languages or contact languages. The resilience of this language is currently being tested with the advent of the SARS-CoV-2 pandemic threatening the lives of older language-keepers. Therefore, the careful creation of tools and frameworks is needed to facilitate society’s creole language needs.
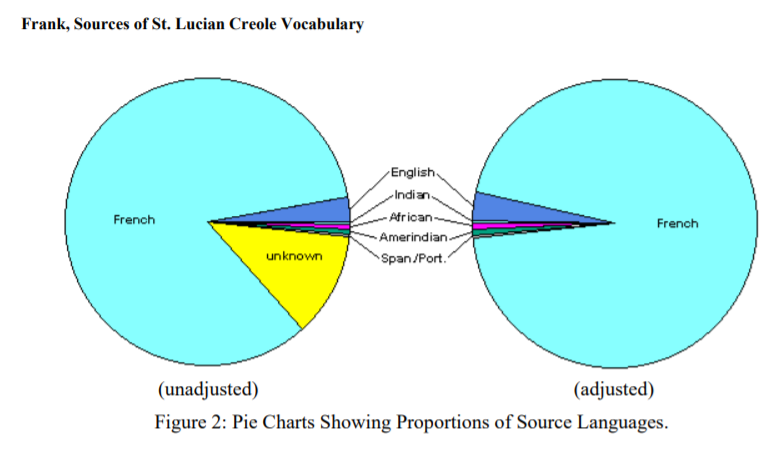
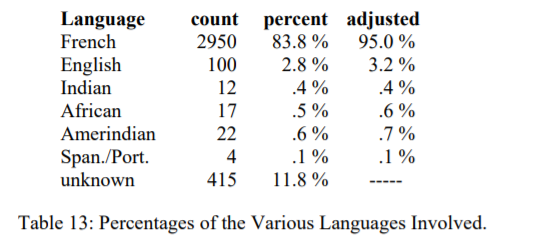
Yet, it is this very discordant origin and complexity of structure that presents issues to the preservation of creole languages. For example, most words in Saint Lucian Kwéyòl/creole focus on emotions, the weather, and other aspects of the natural environment, including animals and food sources (Frank, 2007); therefore, finding domain-equivalent literature sources outside of certain contexts can be challenging. Moreover, it is said that just over 83% of vocabulary words have French origins; roughly 3% is English-based, and Amerindian, African, and East Indian sources account for about ½ % of the total each (Frank, 2007). Even the author of the official creole dictionary acknowledged gaps in its vocabulary was due to the lack of official etymological details of over 11% of documented words (Crosbie et al., 2001; Frank, 2007). Despite the advantage of cross-referencing parallel language data sources, the language challenges are made more complex by many of the vocabulary words lacking details on their origins. Ultimately, the situation could be described as a “Mondrian-like” language setting. This image seems apt to explain this low-resource creole being close to parallel and monolingual data with high-resource languages (like French and English), yet the present language data may belong to different domains (missing reference).
Not much NLP research has been done on adapting its components to creole languages, however, the academic tide has been changing as of 2020 (Soto, 2020). As of early 2020, Stanford provided a course on Low Resource Machine Translation. And as of late 2020, even Carnegie Mellon University curated courses in Multilingual NLP and Low-resource NLP.
There are multiple ways to utilize NLP functions when addressing language challenges. The increasing popularity of opinion-rich resources such as blogs (Joseph, 2020), shopping websites, review portals, and social media platforms (Joseph, 2020) are rapidly attracting business people, governments, and researchers alike. Sentiment analysis often garners high interest from businesses. However, there are challenges present in natural language processing, particularly when dealing with sentiment analysis, word-sense disambiguation, and issues with dependency parsers in cross-lingual settings. A major challenge of lexical semantics is creating training data and algorithms that facilitate downstream tasks.
Moreover, it has also been said that while there is a lingering ‘bias towards contemporary Indo-European languages’, treebanks for other language families and treebanks for classical languages are on the rise (Nivre et al., 2016). It has been suggested that categorizing the challenges and formalizing their interpretation using Universal Dependencies may help create a Saint Lucian Kwéyòl dependency treebank, and later facilitate other needed NLP tasks (such as sentiment analysis of texts). A Saint Lucian Kwéyòl parser may be constructed by leveraging the base knowledge of French syntax. However, these may not be the only tools required to tackle the challenges of digitizing and analyzing creole languages. Therefore, it may be helpful to develop a framework to improve the models for linguistics. Perhaps an extendable framework that can demonstrate its application to low-resource creole languages.
The Goal:
In summary, David Frank’s paper on Sources of St. Lucian Creole Vocabulary piqued my interest, particularly the section on Vocabulary of Unknown Origin. Creole is complex as it is an amalgamation of different languages adapted for survival and solidified through generations of oral and written communication. I became intrigued by the complexity and mysteries within Saint Lucian creole “Kwéyòl” and hoped to explore it through data science tools and techniques.
Draft methodology:
Currently, I am leaning towards using multilingual natural language processing to create a language detection and translation model capable of tracing the origin of Saint Lucian creole “Kwéyòl” by exploring supervised and unsupervised Statistical Machine Translation. However, in order to do so, I must also explore and understand the underlying language structures; such as dependency parsing, treebanks, sentiment semantic indexing on multilingual data.
I am also intrigued by topics on word sense disambiguation in creole; particularly the problems polysemy poses to sentiment analysis and how that impacts machine translation in low-resource languages. I want to explore phrase-based parsing techniques to see how they will impact the accuracy of my machine translation models.
Ultimately, outcomes of this endeavor will include, contributions of new and/ or improved Saint Lucian “Kwéyòl corpora for future analysis, and new techniques and tools for exploring sentiment, and low resource languages. In order to properly explore this topic, I will need to search for and prepare the sample Saint Lucian “Kwéyòl corpora; locating as much parallel data as I can find. I want to use cross-lingual machine translation to find the unknown origins of vocabulary words.
Assumptions:
- Saint Lucian Kwéyòl is a low resource language
- Lexifiers can be assigning ranks based on an established assumed similarity to the target language.
- The official Saint Lucian Kwéyòl dictionary is a work in progress; not fully comprehensive.
- French (fr) is the main lexifier language of “Kwéyòl.
- The official French dictionary is adequately comprehensive.
- English (en) is the current prestige language of Saint Lucia.
- The official English dictionary is adequately comprehensive.
- Additional known contributing languages: Guadeloupean Creole French (gcf), Haitian Creole (hat), Spanish/Portuguese (sp/pt), Amerindian (Carib -car, Arawak -arw,), Indian (Hindi-hi, Tamil-ta), African (Yoruba-yor, Fulani-ful, Bantu-bnt, Igbo-ibo, Kikongo-kon, Mende-men).
- These other contributing languages are low in resources.
- Exploring and categorizing the vocabulary of unknown origin may assist with understanding semantic domains.
- An understanding and focus on cognates is essential to the cross-lingual or multilingual NLP techniques used for language translation and detection.
- The LIWC does not currently factor in all recent Unicode emojis, thus may be a flawed system in detecting the full context of modern social media discussions.
Draft Hypotheses:
-
Hypothesis: In exploring semantic similarity corpus from related yet better-documented languages (such as Haitian Creole and Guadeloupean Creole French) may assist with unsupervised Statistical Machine Translation testing.
-
Hypothesis: While English is the current prestige language of Saint Lucia, and French is the main lexifier language of “Kwéyòl, the origins of the unknown vocabulary are mostly composed of roots from the lesser linked languages (arw, car, sp, Indian, and African) are most likely to hold the remaining details due to their continual depletion.
-
Hypothesis: A novel CNN-based sentiment semantic indexing method can be applied to multilingual data; this should ease/improve sentiment analysis outcomes on Kwéyòl data.
-
Hypothesis: Alpha and beta phrase parsers can reduce issues of polysemy and word sense disambiguation, thus improving sentiment analysis.
-
Hypothesis: the natural annotation of crowdsourced online dictionaries can be useful for building the corpus of a low-resource language, and reducing issues of polysemy and word sense disambiguation, thus improving sentiment analysis.
-
Hypothesis: careful use of social media text can aid in building the corpus of a low-resource language, and reducing issues of polysemy and word sense disambiguation, thus improving sentiment analysis; looking at the intent of discussions/texts of social media.
-
Hypothesis: There is an arguable existence of a connection between ethical data science pursuits, Maslow’s hierarchy, biocultural diversity, and the importance of language preservation in light of covid.
-
Hypothesis: There may be a biocultural diversity link to most creole words as they were created for survival; words are mostly related to nature, food, and relationships.
Establishing a Framework:
Draft modeling for Complex Unsupervised Statistical Machine Translation for Saint Lucian Creole/ Kwéyòl:
The Proposed Framework:
Using back translation to augment or to create pseudo-parallel data from Source language to target language, and then back from the target language to the source language. The source language would be our main lexifier languages, and would, therefore, be more dominant/strong than the other lexifiers being used. For now, I will list dominant first, and will also be looking for language clusters (like French, Guadeloupean Creole French, Haitian Creole, and English).
Dominant/stronger lexifier/source language clusters:
- French: fr → acf acf →fr
- Guadeloupean Creole French: gcf → acf acf →gcf
- Haitian, Haitian Creole: hat → acf acf →
- English: en → acf acf → en en → acf acf → en
Non-dominant/Weaker clusters lexifier/source language clusters:
- Spanish: sp → acf acf → sp
- Portuguese: pt → acf acf → pt
- Amerindian:
- Arawak language (Lokono) arw → acf acf → arw
- Carib language (Kali’na): car → acf acf → car
- Indian:
- Hindi: hi → acf acf → hi
- Tamil: ta → acf acf → ta
- African:
- Yoruba: yor → acf acf → yor
- Fulani: ful → acf acf → ful
- Bantu: bnt → acf acf → bnt
- Igbo: ibo → acf acf →ibo
- Kikongo: kon → acf acf → kon
- Mende: men → acf acf → men
Once a phrase machine translation model is trained in both directions (back and forth), do back translation to augment or to create pseudo-parallel data from those languages (using the phrase-based model that was just built) in an attempt to create iterative refinement on the validation set.
The Obstacles:
Data Science is an actively developing field; due to program lengths for P.h.D programs, it may be very difficult to create a timely yet thorough compilation of all available topics, techniques, and technologies. This endeavor is quite a complicated undertaking to publish as a single contributor. Co-authorship on works may be sought to competently manage the workload of research, and the coding of these tools. Ultimately, the intention is not to compile a comprehensive list of all possible avenues of exploring creole via data science’s NLP tools. It is to encourage interest in the field and provide starting points for possible future expansion of these topics.
The Tools:
The tools may focus on open source and low-cost resources such as R Studio, Python, Dart, Flutter, fastText, LIWC, Github, Microsoft Office 365 tools (like Forms and Power BI), Tensorflow, and other available Google tools available.
- Google Colab can be described as a Python development environment that runs in the browser using Google Cloud; it is completely free of charge, and even offers access to their GPU is free of charge for some hours of usage every day.
References:
- Frank, D. B. (2007). Sources of St. Lucian Creole Vocabulary. http://www.saintluciancreole.dbfrank.net/workpapers/sources_of_vocabulary.pdf
- Crosbie, P., Frank, D., Leon, E., & Samuel, P. (2001). Kwéyòl dictionary. Castries, Government of Saint Lucia, Ministry of Education. http://www.saintluciancreole.dbfrank.net/dictionary/KweyolDictionary.pdf
- Soto, W. (2020). Language Identification of Guadeloupean Creole. Groupement De Recherche Linguistique Informatique Formelle Et De Terrain (LIFT), 53. https://hal.archives-ouvertes.fr/hal-03066031/document#page=59
- Joseph, J. C. (2020). Kwéyòl Sent Lisi. In Kwéyòl Sent Lisi. https://kweyolsentlisi.weebly.com/
- Joseph, J. C. (2020). Kwéyòl Sent Lisi. In Facebook. https://www.facebook.com/kweyolsentlisi/
- Nivre, J., De Marneffe, M.-C., Ginter, F., Goldberg, Y., Hajic, J., Manning, C. D., McDonald, R., Petrov, S., Pyysalo, S., Silveira, N., & others. (2016). Universal dependencies v1: A multilingual treebank collection. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), 1659–1666.