8. Vocabulary of Unknown Origin
Overview:
Modern communication and educational tools can facilitate the ease of creation of new languages as well as the study and preservation of others. The complexity of creoles can demonstrate a unique symbiotic relationship with current language detection tools; for example, the mysteries of a low-resource creole language can be explored, while simultaneously challenging current language detection/ identification tools. For example, within the Caribbean, several creoles exist; many of which are intrinsically linked due to their different yet shared histories of colonization. This work aims to explore the outputs of various modern language detection/ tools when encountering a language not included in their knowledge banks and addresses lingering etymological concerns.
Saint Lucian Kwéyòl can currently be viewed as a low-resource language as it is mostly orally passed on, has a fair degree of polysemy, its current vitality is unknown, and is unavailable via most modern language detection and translation tools. Moreover, it bears etymological mysteries that David Frank manually annotated in his 2007 work ‘Sources of St. Lucian Creole Vocabulary’ (Frank, 2007). With the resources available to him at that time, Frank was able to identify Saint Lucian Kwéyòl Vocabulary of French, English, Indian, African, Amerindian, and Spanish or Portuguese origin (Frank, 2007). And yet, one of the last sections of that work highlighted that almost twelve percent of his language dataset consisted of ‘Vocabulary of Unknown Origin’ (Frank, 2007). This Saint Lucian Kwéyòl language and the mysteries of its unknown vocabulary list will be the focus of this investigation.
Literature review:
Living languages can continuously evolve as long as it is learned and spoken by the youth of the population. Creoles are the evolved forms of pidgins where the language has set rules passed on as the first language of newer generations of the population. Many creoles still exist around the world - some better documented than others.
Note that as of 2018, an assessment of creoles in the Caribbean suggested that while there is at least one dictionary for every French Creole spoken in the French-speaking Caribbean’, ‘the French Creoles of Trinidad, Venezuela, Grenada, and San Miguel (Panama) still do not have a dictionary’ (Siegel, 2018). This, therefore, can also imply that these languages would also be excluded from most modern language tools. Saint Lucian Kwéyòl (also known as Saint Lucian Creole French, Kreyol, Kwéyòl, Patois, or Antillean French Creole), is one such language. It is currently absent from most modern language detection/ translation tools such as the GoogleTranslate app.
The three-character code of ‘ACF’ (based on the aforementioned name of Antillean French Creole) was bestowed upon the Saint Lucian Kwéyòl by SIL International (formerly known as the Summer Institute of Linguistics); this was done in conjunction with the ISO (International Organization for Standardization) (SIL, 2021). The SIL has had an extensive relationship with Saint Lucia and the study of this language. The SIL worked with the Saint Lucian government to publish one of few official dictionaries for the language and used this to aid with the translation of the Christian Bible. Representatives of SIL also aided with the cataloging and publishing of other literary works (such as folktales) and assisted with the promotion of the language’s written form via creative writing workshops. David Frank was one of the main contributors to this effort, and his works provide useful insight from a formal linguistic perspective.
And yet, despite SIL’s recognition of this language’s uniqueness (including their Saint Lucian Kwéyòl is not the sole user of the ACF language code. Since some believe that Saint Lucian Kwéyòl shares a high degree of mutual intelligibility with the creole from the island of Dominica, they are grouped together; thus being recognized as Antillean Creole (French) - ACF. Neither language is recognized by most modern language detection and translation tools.
Despite the existence of a language code from SIL, ACF is yet to be included in the Library of Congress’ ‘Codes for the Representation of Names of Languages’ (of Congress, 2013). Overall, while Saint Lucian Kwéyòl is believed to be a living language, there is no definitive quantifiable modern study to confirm if the language is still spoken among the majority of the island’s inhabitants or spoken among the youth as a first language (SIL, 2021). One could deduce that this lack of quantifiable information may negatively impact modern organizations’ and institutions’ motivation to include such a language in their offerings.
In 2007, David Frank explored the ‘Sources of St. Lucian Creole Vocabulary’ (Frank, 2007). He attempted to quantify the etymological composition of the language, however was unable to identify the origin of all of the vocabulary he encountered. It should be noted that Frank did include a few annotations of his attempts at addressing the issues with a vocabulary list of items of unknown origins. He suggested that some of these could indeed have a French source, but that he could not provide a precise French form that adequately matched up with the Kwéyòl equivalent (Frank, 2007). While not all words of this list would have links to the French language, ‘ankléwant’, ‘finisman’, ‘hayisans’, and ‘kléwé’, were noted as possibly having French sources. Thus the existing hypothesis is that most of the unknown words may have French sources that are yet to be revealed.
However, when dealing with creoles, it is possible to consider that a language believed to have a strong influence on a creole, a potential lexifier language, might be quantifiably less influential than expected, while substrate ‘contact’ languages seem to compete for the positions of in Recent works can be found exploring the possibility that while the established origins of Caribbean creole languages can be explained by the impact of historical events (colonialization and slavery), coupling this history with quantitative analysis may reveal more accurate findings.
As of 2019 Wiesinger, suggested that there was ‘‘[no] numerical predominance of lexical Gbe influence on Guianese (the largest creole language of French Guiana) (Jacobs & Parkvall, 2021; Wiesinger, 2019). Contrarily, the words of Gbe origin (29%), actually outnumbered those found to be related to the Bantu languages (37%) (Jacobs & Parkvall, 2021; Wiesinger, 2019); moreover, the majority of the words that were assumed to be unique to the Guianese creole language, as a result of its complex history, were actually also present in other creoles such as Haitian, Saint Lucian Creole, and Suriname Creoles’’ (Jacobs & Parkvall, 2021; Wiesinger, 2019). Jacobs built on Wiesinger’s ideas and was able to effectively argue that ‘when reconstructing linguistic history, linguistic data, rather historical, should (other things equal) receive priority and govern our thought process’ (Jacobs & Parkvall, 2021).
These works encourage others to approach an investigation of a creole language’s origins in a methodical, logical, and quantifiable manner; that one should use all available resources and technologies, rather than simply accepting all assumptions outlined in the limited previous works on these matters. Ultimately, one could suggest that perhaps some of the items on the vocabulary list of unknown origin, might also have more of an influence than expected from previously unexplored language options, such as the Bantu languages.
-
need to include more literature review details ACF? Or at least something else before discussing the following paragraph. I can’t remember what I wanted to add before this right now
-
need to include literature review details on other currently available language detection/identification software/tools
-
need to include other details concerning the exploration of words by dimensions matrix
-
Explain how words by dimensions matrix will be used here, discuss synsets and synset in cases of polysemy.
-
discuss wordnet/Euronet/ BabelNet? BableNet may be interesting as it would include a multilingual perspective but may not reveal etymology. I am unsure of the language detection function for these, however, there may be a translation and etymological value present.
Methodology:
Statements:
Since most modern language tools do not currently accommodate the many creole languages, Saint Lucian Kwéyòl, a currently excluded language, was used to explore their capacities.
-
This study also sought to prove or disprove Frank’s hypothesis that most of the unknown vocabulary is likely to have French origins. However, another hypothesis being explored was quite contrary to this idea.
-
It was based on the hypothesis that the percentage of unknown vocabulary with Indian language origins was higher than currently assumed (and is possibly beyond the current assumed semantic domain of food items or descriptors of persons bearing Indian ancestry).
-
One can also hypothesize that while these tools would not accurately detect (and translate) the list of Saint Lucian Kwéyòl language vocabulary of unknown etymology, underlying etymological links could be drawn from languages detected and their output. Therefore, it was speculated that if similarities were uncovered, the languages’ actual dictionaries would serve as a more direct unveiling of the shared etymology (Crosbie et al., 2001). The output could then be clustered for ease of viewing and additional analysis. It should be noted that detection and translation can often be intertwined in etymological research, as one can attempt to justify a detection through an apt application. The translation is not always needed, however, in instances where the etymological links are in question, support from translation may have a positive impact.
-
Ultimately, dimensions matrix models (customized semantic similarity multilingual models) were assumed to be more adept in exploring and identifying language similarities and etymology details, than utilizing less customizable publicly available tools and techniques, such as Google’s language detection tools paired with manual annotation. It was also expected that due to the fair degree of polysemy present, the output may bear multiple synsets.
Overall, several attempts were made to explore the current capabilities of popular language detection/translation tools capabilities. This began with the basic observation and annotation of the output of these tools, an additional pass to confirm specific details, checks against other modern language tools, and then cross-referencing notable items with actual dictionaries of the languages. For example, actual French (FR) and Haitian creole (HT) dictionaries were used to explore the etymology of words that presented a high degree of similarity to Saint Lucian Kwéyòl. Direct text comparisons were made, as well as reviewing their English translations.
Further exploration included a customized quantifiable check on the word similarities. This exploration was conducted on the entire dataset; yet, also included a specific focus on the vocabulary that had been manually annotated by Frank, and those manually highlighted in the aforementioned exploratory phases. Ultimately, creating a code to automate and link these tasks should improve future efforts at using data science to decipher details of other current creole languages, and other emerging creoles.
Tools:
Ultimately, all of the data from the unknown vocabulary list was passed through several language detection/translation tools. Google, Lingua, etc, are such tools. Google’s tools are the most popular; since Google offers multiple tools, the vocabulary list was extensively explored using this company’s offerings. In fact, an initial check was performed on the data, and the output was followed up with a secondary exploration for further clarification.
The vocabulary list was run through two free language detection tools offered by Google. These being GoogleTranslate web application (translate.google.com) and the Google Spreadsheet function (=GOOGLETRANSLATE(DETECTLANGUAGE(X)) via a personal docs.google.com/spreadsheets account). Both were used as a means of confirming or clarifying details for a more comprehensive final output. For example, the results of the GoogleTranslate application can suggest alternative spellings or other possible languages with tweaking of characters or context. However, it only has the exact name of the detected language, but no language code. The Google Spreadsheet can suggest a language code and thus detect a language, however, it is a flawed tool. Some codes appear to be outside of the established ‘Codes for the Representation of Names of Languages’ (of Congress, 2013), and thus appear to incorrectly detect some languages. While issues, such as detections of English words being recognized as ‘on’ rather than the standard ‘en’ can be present, this tool’s output can be used to confirm those of GoogleTranslate. Yet, occasionally, the output can indeed diverge from GoogleTranslate. These instances can, however, be viewed as useful to the refining of overall language comparison options. Notes were made on such observations.
- need to include how other currently available language detection/ identification software/tools will be used
Results and Discussion thus far:
Google’s Tools:
*So far I have created a Google spreadsheet to note the results of both tools when compared to the definitions of Frank’s ACF dictionary.
As noted before, Frank did attempt to address the issues of the vocabulary list by suggesting that most of these words might have French sources. However, only a few words in this dataset were ultimately detected as French. The strongest connection had been with Frank’s annotation that the French’s ‘soeur’ had a direct connection with ACF’s ‘sésé’ (sister). This assumption was supported by both Google tools.
{kind=link}
In other instances, Haitian Creole was detected and indeed aligned with the Saint Lucian Kwéyòl word. For example, ‘soudè’ (meaning ‘deaf person’), was detected as Haitian creole and translated simply as ‘deaf’. Frank indicated that this word had French origins from ‘sourd’ (meaning ‘deaf’). This was confirmed via a direct Google tool translation from English to French, and reinforced by a French dictionary source.
However, it should also be noted that some words that visually appear to be associated with a certain language, would not be revealed as such. For example, Frank suggested that the Saint Lucian Kwéyòl word ‘valowab’ (meaning ‘valuable’) was associated with the French’s ‘valeur’. However, Google’s language tools, this word was not detected as French, Haitian, nor any African language, that one might assume. In fact, it was detected as being ‘Estonian’; yet there was no translation provided to clarify this association.
A similar outcome was seen with the Saint Lucian Kwéyòl word ‘bazoudi’ (meaning ‘stunned, dazed’). Both Google tools detected this word as ‘Chinese’, yet did not provide an actual translation. In this case, Frank did not include an annotation to suggest a French origin. However, when ‘stunned, dazed’ was checked against both French and Haitian offerings of GoogleTranslate, they visually appeared to be similar; the outputs were ‘abasourdi’ and ‘etoudi, etoudi’, respectively. Their dictionaries also supported this association.
On the other hand, there were instances where words did not visually appear to have a connection to a language, yet, the tools (and annotations) suggested that one existed. For example, Frank suggested that the word ‘ankléwant’ (shiny) had a French source, ‘clair’ (light). This assumption was supported by both Google tools. However, the actual translation was not displayed. Further investigation suggested that ‘clair’ could also be translated to ‘clear’ or ‘bright’; these have a fair level of semantic similarity with ‘shiny’. Interestingly, another word also on the unknown vocabulary list did strengthen this French connection between ‘ankléwant’ and ‘clair’; Kléwé’ (to shine) was also annotated to have a connection to the French source word ‘clair’. However, to seemingly add further confusion, kléwé’ was detected as Sundanese (yet, no translation was given).
In fact, at least seventeen (17) items were detected as Sundanese, and at least one more word was originally annotated as French. Frank noted ‘wépantisman’ (repentance) as having a connection to the French word ‘répentir’ (repentance), yet the Google tools detected it as Sundanese. In observing this confusion, one could assume that ACF appears to, at times, replace ‘r’ sounds with ‘w’ sounds, thus causing issues for the detection tools. The question then would be why does this occur, and if it occurs in other languages; if so, perhaps those languages might provide additional helpful information. *Perhaps all the words detected as Sundanese might need to be run through a French translator to see if any other underlying connections could be revealed. *
The majority of the source vocabulary list was actually detected as being Haitian Creole - another creole language within the same region. While about 26 instances of French were detected, at least 127 instances of Haitian creole were detected during the initial exploratory phase. However, the majority of words detected as Haitian Creole did not appear to share meanings with Saint Lucian Kwéyòl during that phase. This, therefore, made attempts at etymological associations difficult to justify without additional exploration.
However, it should be noted that upon a second passing, the number of similarities increased. It does appear that both HC and ACF have high levels of polysemy. When consulting multiple actual Haitian dictionaries, the second available definition was often the one that was actually shared. It appeared that in those cases, Google’s tools failed to display the option most relevant to this study.
Moreover, while one of the official Haitian dictionaries does have the exact same meaning and phrasing “deaf person”, it did not state the word’s etymological details. In fact, most words in all Haitian Dictionaries used did not include etymological details; only a few of French or Spanish origin were included. While this would seem to support Frank’s assumption that most of the vocabulary is actually French (with the aid of a Haitian connection point), not much of the shared vocabulary in this dataset revealed the needed etymological details.
Confusion with polysemy also arose when discussing a word shared by both languages - ‘fòs’, meaning ‘force, strength’. Saint Lucian Kwéyòl assigns an additional meaning to the word; the etymological mystery lies with its use as ‘furrow, mound, heap, hillock, knoll for planting’. This issue also occurred with the word ‘manm’. Both share the meaning of ‘member’ (of a group), however, the etymological mystery lies with its utilization as ‘muscle’. The word ‘Mèyè’ also experiences this confusion. Both words can be used as the adjective ‘better’, yet the etymology details of the additional use as the title of ‘Mistress’ is unknown. In the Haitian dictionary, the word ‘davwa’ would translate to the conjunction ‘for, because, as, since. (pop) More common is ‘paske’. Davwa’l fè sa yo pini’l Because he did that they punish him.
And yet, definitions appeared to be shared in the presence of additional context such as articles. While this outcome may not apply to all other languages, this was a notable observation with Haitian Creole. For example, gòl in ACF translates to ‘robe, gown’, yet Google’s tools detected it as HT and translated it as ‘goal’. However, when reviewing an actual HT dictionary, ‘ròb la’ is comparable to the English word ‘robe’ or ‘dress’; yet some sample sentences did not use such articles (Pran ròb - To take the veil, enter religious orders. Ròb jip a kòsaj - A two-piece dress (blouse and skirt)) (Targète & Urciolo, 1993).
Moreover, the ACF word ‘bitasyon’ translates to ‘countryside, estate’, and is detected by Google tools as HT; a base similarity can be observed as the tools translate this to ‘farm”. However, one can state that translation using actual dictionaries may be more alike with the inclusion of one or two characters that aid with context. One dictionary noted the following output ‘abitasyon an, labitasyon an, bitasyon an n 1. Plan tation, farm, habitation*. Rural farmhouse (dwelling) during colonial times including land around it’ (Targète & Urciolo, 1993).
On an interesting cultural note, though both Saint Lucian and Haitian cultures share the presence of practitioners of supernatural arts, it was surprising that the vocabulary on the matter was not shared. Nonetheless, Haitian Creole did have the most instances of possible vocabulary overlap.
Manual annotations noted some possible similarities in scattered among several languages. For example, “awa” (meaning ‘No! Oh no!’; typically used to express pity, surprise, or disbelief) was translated as “pity” in the Cebuano language (Ceb). Additionally, “chwichwi” (meaning ‘to whisper’) was translated as “squeak” in Welsh. Notably, these similarities appear to be linked to sounds and possible onomatopoeia.
The scope had to be narrowed for drawing similarities with manual annotation to reduce possible interpreter bias and subjectivity. For example, one could make the case for similarities in the meaning and application of the word ‘galè’ While this is yet another word with multiple meanings in Saint Lucian Kwéyòl, its reference to woodwork ‘plane’ may be associated with Haitian Creole’s use as ‘galley’; both relate to carpentry.
Thus far, between four and eleven words were found to overlap in spelling and have matching or similar meanings. The results are in Table 1. For example, the word ‘fanmchay’ is recognized as ‘midwife’ in both languages.
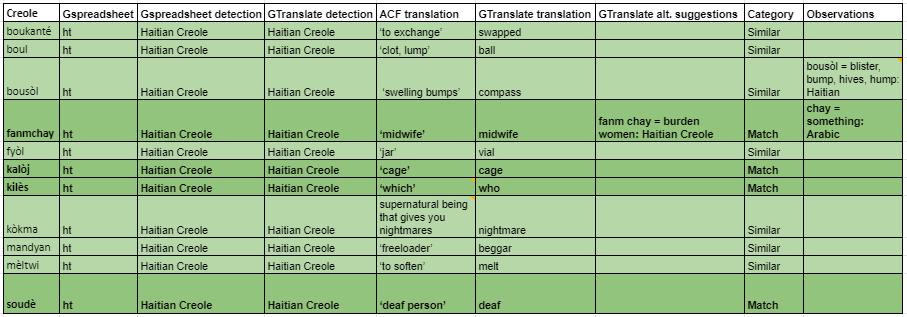{kind=link}
Overall, it should be noted that there were some inconsistencies between the output of the two Google language detection tools. For example, it did appear that some words were detected as Belarusian via the Google Spreadsheet, yet Finnish via GoogleTranslate. This also occurred with Bengali (with the former) and Bangla (with the latter). Other words were detected as English via the Google Spreadsheet, yet Swedish with GoogleTranslate, or viewed as Hungarian with the former, yet English or Dutch with the latter.
Detection of such words as ‘las’, ‘pijé’, ‘tan’, ‘taza’, and ‘waz’, appeared to be the most problematic. Google Spreadsheet struggled to provide a singular suggestion, and so provided the non-standard language code ‘it is’, which could be interpreted as bearing Italian and Icelandic options. However, GoogleTranslate detected most of those words as either Italian, Spanish, or English. This could be due to some word structures (stems, etc.) being shared or being to others within the same Romance language grouping (DeGraff, 2009); Spanish, Italian, Romanian, Portuguese, and French fall into this category, however, Spanish and Italian appear to be difficult to decipher.
Moreover, Google Spreadsheet produced random codes for languages that GoogleTranslate appeared to handle better. For example, some words that GoogleTranslate detected as Catalan, Google Spreadsheet provided a non-standard language code of ‘that’. Other instances included Sundanese words noted as ‘its’, Esperanto as ‘it’s the’, Corsican as ‘What’, Arabic as ‘With’, Japanese (and Estonian) as ‘and’, Turkish as ‘trick’, Vietnamese as ‘we’, and Nyanja as ‘new’.
At this point, one could state that, overall, Google’s language detection tools are less accurate than their translation offerings when dealing with creole languages not included in their knowledge base. There were several detection issues, however, directly pairing the words with specific language and checking their translations did appear to be beneficial. While the translation tools were often incorrect due to underlying language complications (such as polysemy, hypernymy, hyponymy, and part meronomy), they were useful in the initial exploratory stage.
Ultimately, one could state that some of the unknown vocabulary words may indeed have French origins, however, they may be based on ‘Old French’ (and possibly Germanic). In fact, these particular words may be hybrids, a mix of Old French with a few influences of other languages (thus spellings being off by a few characters). For example, the ACF word ‘gwaté (to scratch, to scrape), was excluded from this problematic vocabulary list as it was definitively associated with the modern French term ‘gratter’ (to scratch) (Crosbie et al., 2001; Frank, 2007). However, while ‘gwajé’ (to grate) is detected as Sundanese (with no translation) the etymology of ‘grate’ is generally accepted as being from Old French grater (and of Germanic origin as ‘kratzen means ‘to scratch’.) (Frank, 2007). Modern French uses ‘râper’. There may be an additional language influence from one that replaces the sound ‘te’ or ‘té’ with ‘j’.
Other tool discussion:
General discussion:
References:
- Frank, D. B. (2007). Sources of St. Lucian Creole Vocabulary. http://www.saintluciancreole.dbfrank.net/workpapers/sources_of_vocabulary.pdf
- Siegel, J. F. (2018). Lexicography in the French Caribbean: An Assessment of Future Opportunities. The XVIII EURALEX International Congress, 192.
- SIL. (2021). ISO 639-3 |SIL International. In ISO 639-3. SIL International (formerly known as the Summer Institute of Linguistics). https://iso639-3.sil.org/
- of Congress, L. (2013). Codes for the Representation of Names of Languages. In ISO 639-2 Language Code List - Codes for the representation of names of languages (Library of Congress). Library of Congress. https://www.loc.gov/standards/iso639-2/php/code_list.php
- Jacobs, B., & Parkvall, M. (2021). How Gbe is Guianese French Creole? Lingua, 250, 102939.
- Wiesinger, E. (2019). Non-French lexicon in Guianese French Creole: A sociohistorical and linguistic study on the African contribution. Journal of Pidgin and Creole Languages, 34(1), 3–48.
- Crosbie, P., Frank, D., Leon, E., & Samuel, P. (2001). Kwéyòl dictionary. Castries, Government of Saint Lucia, Ministry of Education. http://www.saintluciancreole.dbfrank.net/dictionary/KweyolDictionary.pdf
- Targète, J., & Urciolo, R. G. (1993). Haitian creole-English dictionary. Dunwoody Press.
- DeGraff, M. (2009). Language acquisition in creolization and, thus, language change: some Cartesian-Uniformitarian boundary conditions. Language and Linguistics Compass, 3(4), 888–971.